Optimizing Flappy Bird World Model to Run in a Web Browser 🐤
TLDR: I trained a Flappy Bird world model to run in your web browser, try out the demo here!
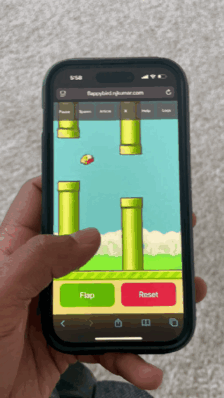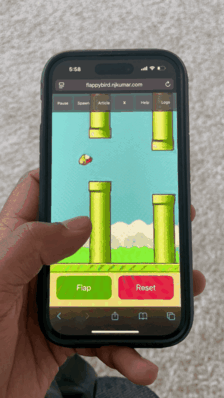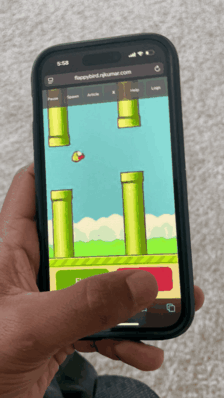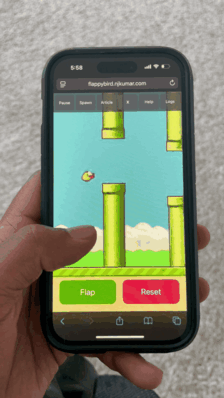
Flappy Bird world model running in Safari on iPhone 14 Pro
Recently, I’ve been pretty interested in world models, which build on video generation research to create real-time simulations based on a user's input. I’ve seen them being applied everywhere from creating environments for autonomous vehicles and robots, to video games that can generate the physics, rules, and graphics without embedding any of the traditional game logic into the program. Decart’s viral AI Minecraft project, Odyssey's interactive videos, Runway's general world models, and Google’s Genie 2 are cool examples of this being applied to the gaming/film industry, and I think there will be a future where people can generate and re-style games and films entirely from their laptops and phones, with infinite control and customization.
However, if companies want to serve these world models effectively, they need to let users play with the model in real-time with little to no latency. There are two scenarios I see in how people will actually interact with these generative games.
The first is what I see as the default, where GPUs are hosted on servers and users wait in a queue to access the demo. When it’s your turn, you’re allotted a limited session of 3-5 minutes to run the model. Decart’s Minecraft model and Odyssey’s demo are two examples of this approach.

Video models (and by extension world models) run inefficiently on GPUs because generating frames is extremely compute-intensive. There are workarounds, for instance Decart built a custom inference stack from scratch on Etched’s Transformer chips and scaled to over 2 million users in 4 days. FAL is building a specialized inference engine that excels at video generation, and these developments should translate to building more efficient world model infrastructure. However, even with these optimizations, I still think we're heading towards a bottleneck. Running a model continuously for 3-5 minutes will remain expensive, and as world models gain popularity, the demand will quickly overwhelm any available compute.

Inference crunch applies to world models as well!
The other option worth exploring is running these world models directly on user devices. This limits the model size and complexity, but I think there are some interesting advantages, such as zero server costs, zero session limits, and most important wide distribution. I think back to the original DALLE-mini launch a couple of years ago, and part of why it exploded in popularity was because it was easy to share your creations and interact with the model on any device. World models could work in a similar way, in that you could share a game that runs instantly in a browser, which is almost like a new interactive video format! Ollin’s neural demo prototypes are cool examples of this in practice. The technical challenge would be fitting a compute-intensive model into a constrained environment like a browser, but I think this is a viable path to making world models accessible to everyone, which is what I want to explore in this post.
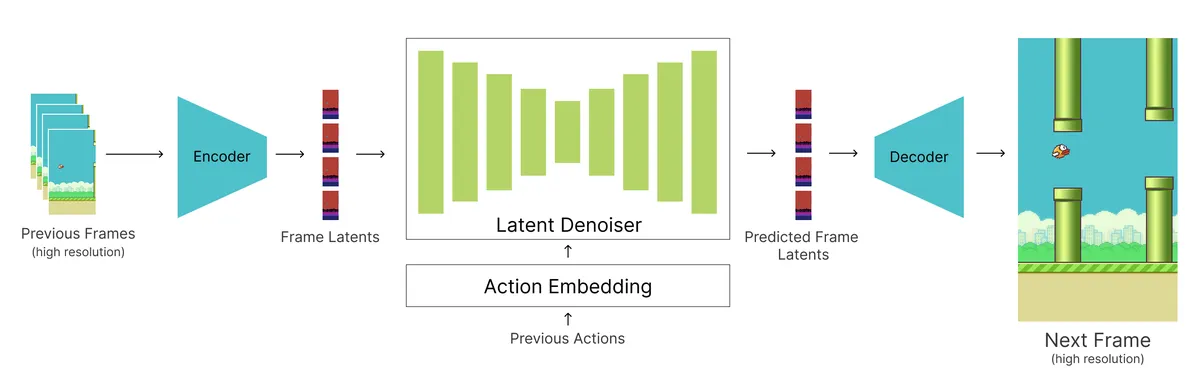
Model architecture and setup
I wanted to use Flappy Bird as my example to illustrate this approach. It’s a simple 2D platformer game that should work well for a smaller model since there isn’t too much visual diversity that we need to worry about, which means we can optimize it heavily. I’m building on the DIAMOND Diffusion architecture, which uses a two-stage diffusion UNet setup consisting of a base denoiser and a small upsampler. The denoiser takes in past low-resolution frames and the previous action sequences and noise level conditioning to generate the next low-res frame, and then the upsampler UNet scales up this frame to a higher resolution for display.
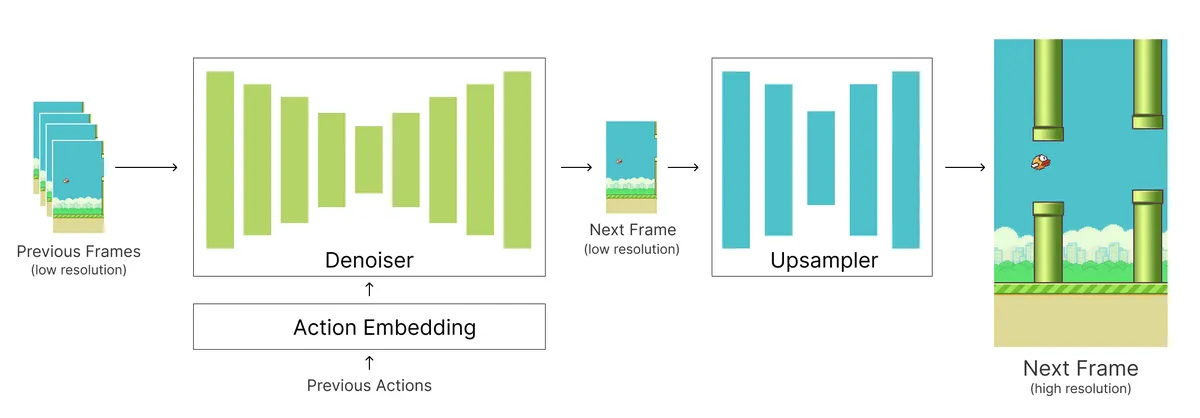
There are three actions baked into the encoder: FLAP when the bird jumps up, NO FLAP when the bird is falling, and RESET to restart the game from the beginning.

I won’t go too deep into the training details here, but I collected a couple of hours of Flappy Bird gameplay using the three actions above. My dataset is a mix of manually collected gameplay, expert robot play, and random bot data to capture diverse and out of distribution scenarios. For a more comprehensive training guide, check out Derewah’s blog post.
After training my base model, I convert the PyTorch model to ONNX format for web deployment via WebGPU. For my benchmark, I’ll be using my MacBook M2 Pro (19-core GPU), and will be measuring the inference time for both the denoiser and upsampler. This combined time will determine our real-time FPS, which is the key metric we want to increase.
Base model

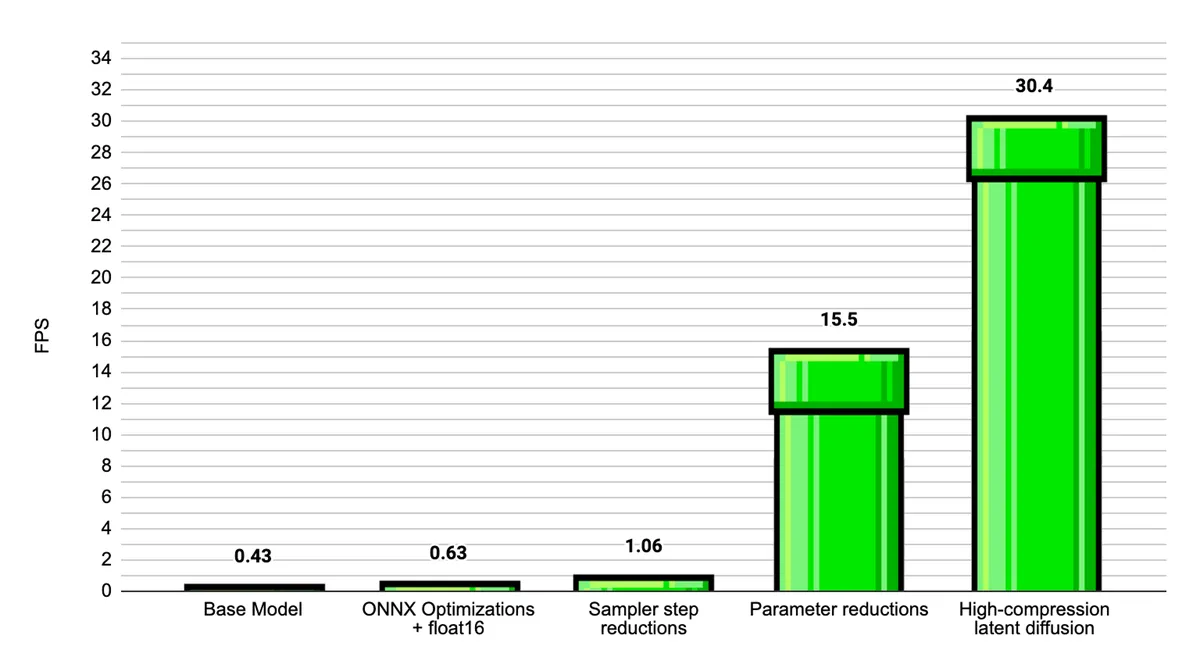
Our base model is over 381M parameters (330M for the denoiser, 51M for the upsampler). On average, it takes about 5 seconds to load, and generates frames at about 0.42 FPS 😬. Not good! This model is really over-parameterized for Flappy Bird, and we don’t need such a large model to generate our frames. There is a lot of low-hanging fruit that we can score some quick wins with before going into more major optimizations.
Denoiser: 620.4ms - 25.8% of total
Upsampler: 1780.0ms - 74.0% of total
Display: 4.2ms - 0.2% of total
Total per frame: 2404.6ms
Estimated FPS: 0.42
Optimization 1: ONNX and float16 + display fixes
ONNX isn’t as well supported as PyTorch, but it’s the de facto way to serve models over the web. ONNX is built specifically for inference deployment and cross-platform compatibility, and as a result there are a limited set of operators that the model can use. This means that we have fewer optimization levers to pull at runtime.
There isn’t an equivalent torch.compile function that we can call to get an instant performance upgrade, but we can use a higher opset version during conversion to get a quick FPS boost. The ONNX team periodically releases new opset versions that introduce optimized operators, better quantization support, and more memory-aware data types. I found that opset version 18 improved my base model performance, and in my profiling experiments, I measured significant speedups for GroupNorm, Attention, and SiLU operators, which was mainly due to operator fusion.
Besides the ONNX upgrade, there were some low-hanging inefficiencies that I got some quick upgrades:
- Float16 conversion: Casting to float16 cuts the model size in half and boosts performance for WebGPU. There are some problematic operators that need to stay in float32, but most benefit from the conversion
- Display Optimizations: I preallocated canvas buffers and GPU textures, and then optimized memory patterns with bitwise operations. This gave me a 7x reduction in display time.
Combining these changes, we get around a 50% increase in FPS.
Denoiser: 488.9ms - 30.9% of total
Upsampler: 1092.7ms - 69.0% of total
Display: 0.6ms - 0.1% of total
Total per frame: 1582.2ms
Estimated FPS: 0.63
Optimization 2: Diffusion sampler step reductions
In general, more denoising steps produce higher quality frames and smoother action conditioning, since the model has more iterations to encode the user actions into the generated frame. However, this is a major bottleneck in our architecture because each iteration depends on the previous one's output, so we have to wait for each step to complete before starting the next one. This requires a full forward pass through both our UNets, so more steps lead to slower generation. For our world model, we need to find the optimal tradeoff where we minimize steps while preserving acceptable quality for frame generation.
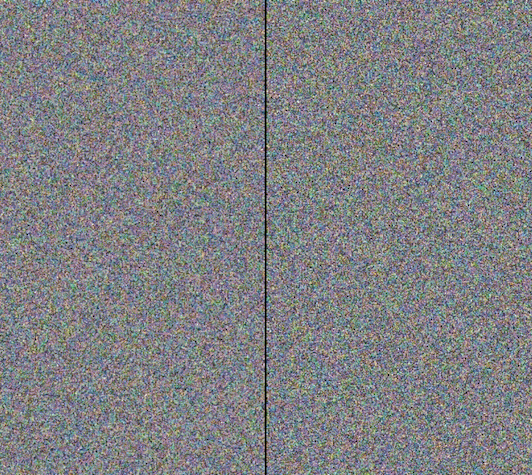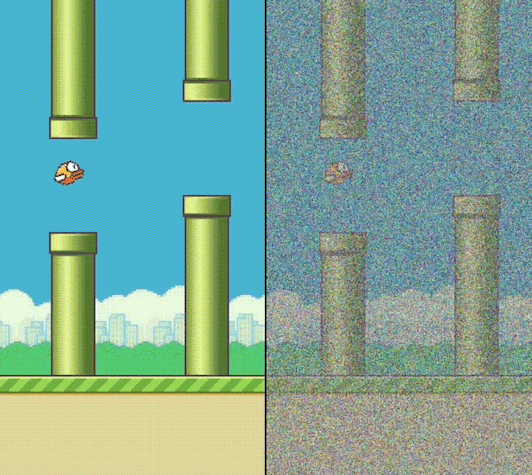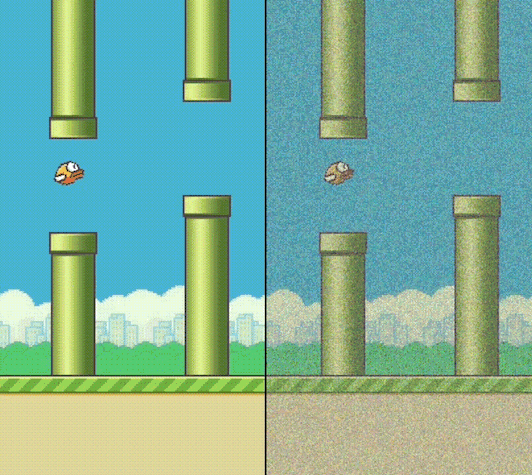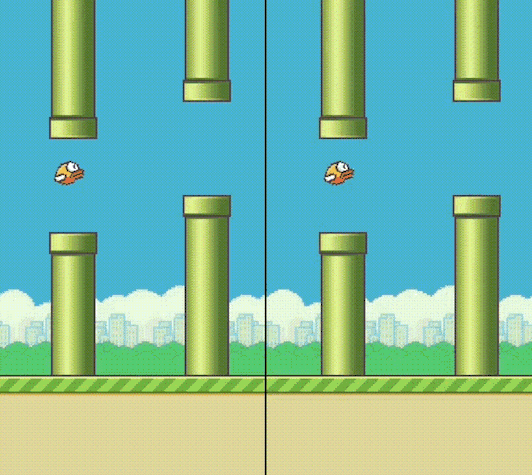
(left) 5 denoising steps (right) 20 denoising steps
Currently for our denoiser, we are doing three passes through our UNet to compute the next frame. If we reduce the number of steps down to 1, we can decrease the frame generation time by 3x. However, now we are trying to remove all the noise from the image and encode the action in one step, which leads to poorer image quality and choppier action behavior. Also 1-step denoising tends to blend and interpolate multiple outcomes together (e.g., crash into pipe, go through the middle) instead of picking one clear outcome, so we can get some weird artifacts and blurry visuals.
Two factors help us with this reduction. First, modeling Flappy Bird is pretty easy in that we have simple 2D graphics that don't require perfect denoising, so we can get away with 1 step and actually still get acceptable quality. Second, the DIAMOND architecture uses EDM as its diffusion formulation, which can maintain stability even with a few denoising steps. In contrast, older approaches like DDPM become pretty unstable with fewer steps. DDPM was designed to take many small denoising steps, so trying to remove all the noise in 1 step makes the jump too unstable and produces poor results. In contrast, EDM is designed specifically for variable step counts, allowing us to handle aggressive step reductions while still producing stable results.
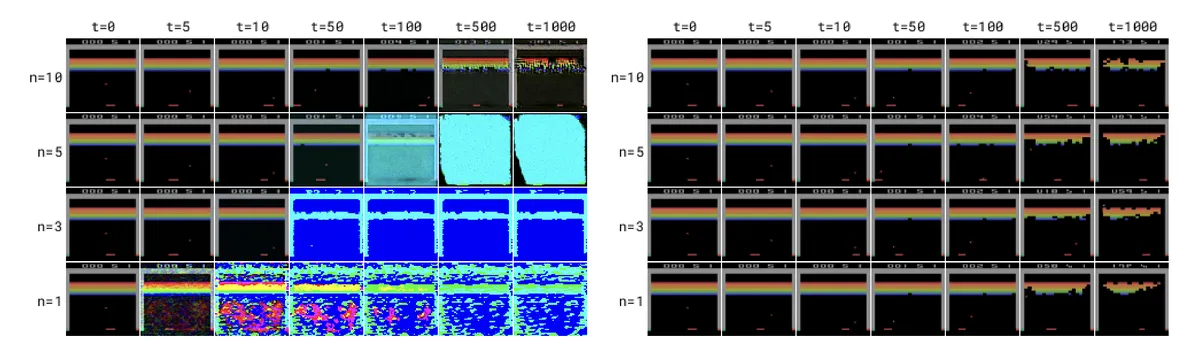
(left) DDPM (right) EDM stability comparison across timesteps (n=1 to n=10) Source: DIAMOND paper
For our upsampler, it’s already set to 1 step, but I found that there is a lot of unnecessary overhead in the sampling scheduler. The DIAMOND repo uses the Karras scheduler, which adds overhead for noise scheduling and generation, and solver checks for each step. This makes sense for the denoiser, which needs to generate entire frames from noise, but the upsampler job is simple, in that we just need to enhance the low-res image.
I experimented with different noise levels and found that using a constant moderate noise value works pretty well. It refines details enough without destroying the low-res image structure, and we can remove the scheduling overhead and only use the fixed value. This reduces upsampler time by almost 300ms.
With the sampler reductions, we get a 68.3% increase in FPS.
Denoiser: 161.4ms - 17.1% of total
Upsampler: 785.0ms - 82.9% of total
Display: 0.6ms - 0.1% of total
Total per frame: 947.0ms
Estimated FPS: 1.06
Optimization 3: Model parameter reductions
We are still far from a playable version, and that is mainly because our current world model is too big! We need to shrink the 381M parameters significantly in order to reduce the computational load performed per frame. Both stages in the world model are multi-layer UNet architectures, and there are several knobs that we can adjust to reduce the model size:
- # of base channels at each layer: Wider channels can handle more complex image patterns
- Denoiser:
[128,256,512,1024], Upsampler:[64,64,128,256]
- Denoiser:
- # of residual blocks at each layer: More blocks enable deeper image processing
- Denoiser:
[2,2,2,2], Upsampler:[2,2,2,2]
- Denoiser:
- # of conditioning channels: Higher dimensions lead to richer action/temporal representation for action embedding + noise encoding
- Denoiser:
2048, Upsampler:2048
- Denoiser:
For the denoiser, I focused mainly on reducing the base channels at each layer and the conditioning channels. My reasoning for this is that Flappy Bird has simple, repeatable pixel patterns and a small number of actions to encode, so I can aggressively cut down these parameters. Reducing the base channels quadratically impacts the parameter count, while reducing the conditioning channels has a linear impact.
For the upsampler, I reduced the base channels, conditioning channels, and the number of residual blocks at each layer. The upsampler is currently our bottleneck, so we need to reduce its processing load. This leads to lower image quality in our smaller models, but we can still get acceptable quality since we are upsampling simple frames. Reducing the residual blocks also has a linear impact on the parameter count.
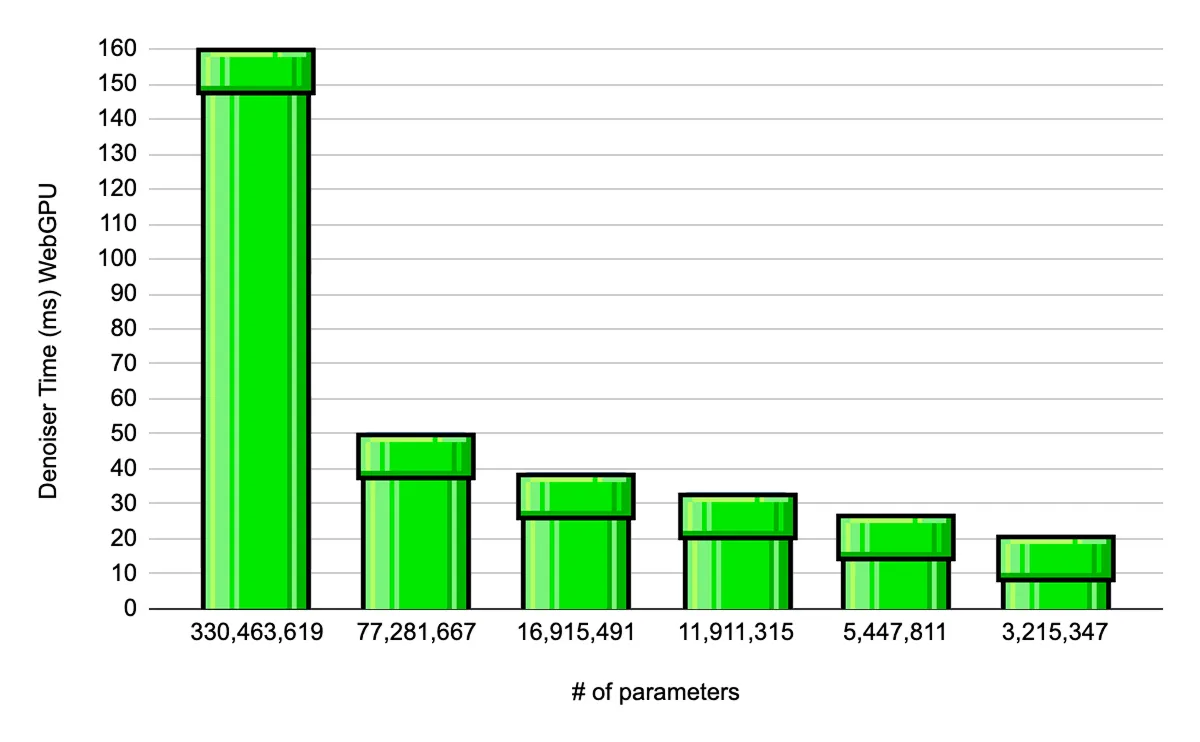
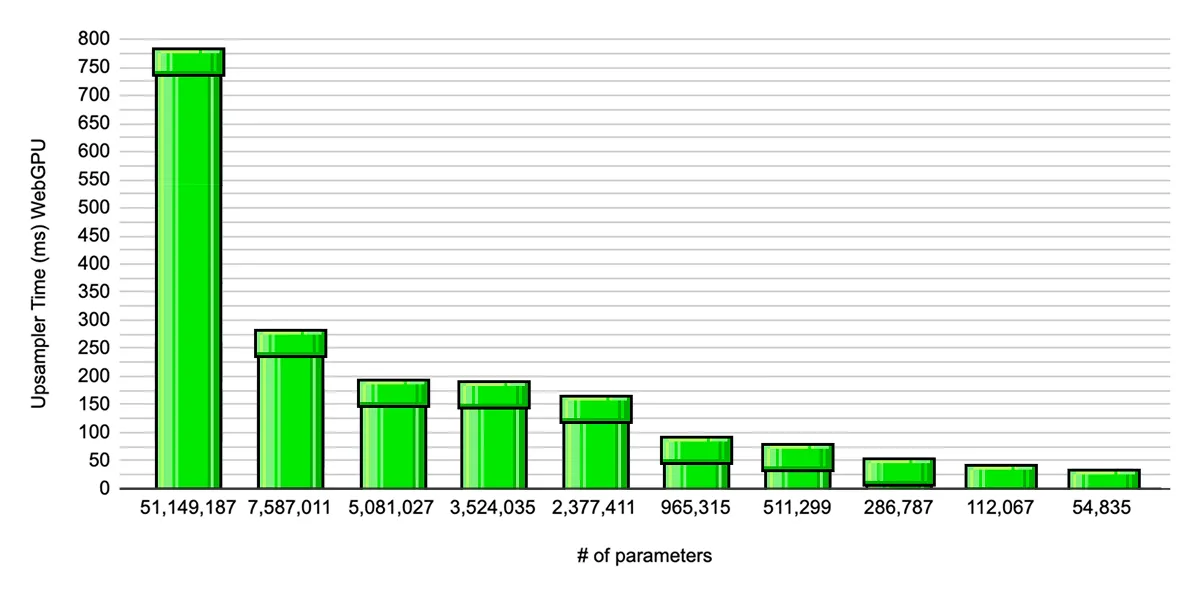
(top) Denoiser (bottom) Upsampler WebGPU inference times across different model sizes
I ran a bunch of ablation experiments to bring down the inference time for both models. This took a while, as I wanted to see how FPS would increase and how the quality looked for smaller model pairs. Smaller UNets in general make more mistakes and can get brittle, so I had to train these models longer in order to generate acceptable frames and recognize the actions correctly.
At around 3.2M parameters, the denoiser started to show some degradation in performance, so I stuck with the 5M parameter model that maintains enough consistency in game state. For the upsampler, the 54K model is unusable and cannot capture the pixels accurately during upsampling, so I went with the 112K parameter model.
Combining the 5M denoiser, and the 112K upsampler, we get a 15x increase in FPS.
Denoiser: 27.1ms - 42.0% of total
Upsampler: 36.8ms - 57.1% of total
Display: 0.6ms - 0.9% of total
Total per frame: 64.5ms
Estimated FPS: 15.50
Optimization 4: High-compression latent diffusion
At this point, we've reached a limit with our upsampler in that we can't reduce it further without ending up with a brittle UNet that can't upsample images correctly. Currently, we train on 64x36 low-res RGB images and use the upsampler to refine them to full resolution. While training on lower resolution saves computation in the denoiser, we lose fine details that the upsampler has to reconstruct, and this adds an entire UNet to our pipeline.
Instead of using a whole UNet for upsampling, I replaced it with a high-compression autoencoder and converted the denoiser into a latent diffusion model. With a well-trained autoencoder, we can encode the full-resolution images into a compact latent space that preserves the essential information about the image, and then accurately reconstruct the image from this latent space at a much cheaper cost than using the upsampler. We can then train the denoiser exclusively on these latent images. For inference, the denoiser runs entirely in the compressed latent space, and we only use the decoder part of the autoencoder at the end to upsample to the full-size image, which dramatically speeds up inference.
To train the autoencoder, I compress the RGB images from my dataset into a 64x36x4 latent space, which is an 8x compression ratio from the original image. The key parameter I tweak in my experiments is the channel width of the autoencoder. Reducing the channels decreases the model’s capacity to learn complex features, but each time we halve the channel size, it gives us a significant reduction in computation time. I tested channel widths of 32, 16, 8, and 4 across 3 downsampling/upsampling blocks, and trained it on MSE loss, which focuses on reconstruction quality at a pixel level.
I chose a basic autoencoder over something like VAE or VQGAN mainly because the Flappy Bird has a pretty simple visual style, and I think we could get away with just using a smaller, performant autoencoder for this use case. Also, I didn’t want to add too much extra complexity in the sampling operations or add any discriminator networks that would increase the compute overhead. For larger and more visually complex games, you would need more sophisticated encoders. Wayfarer Labs is doing interesting research in this domain.
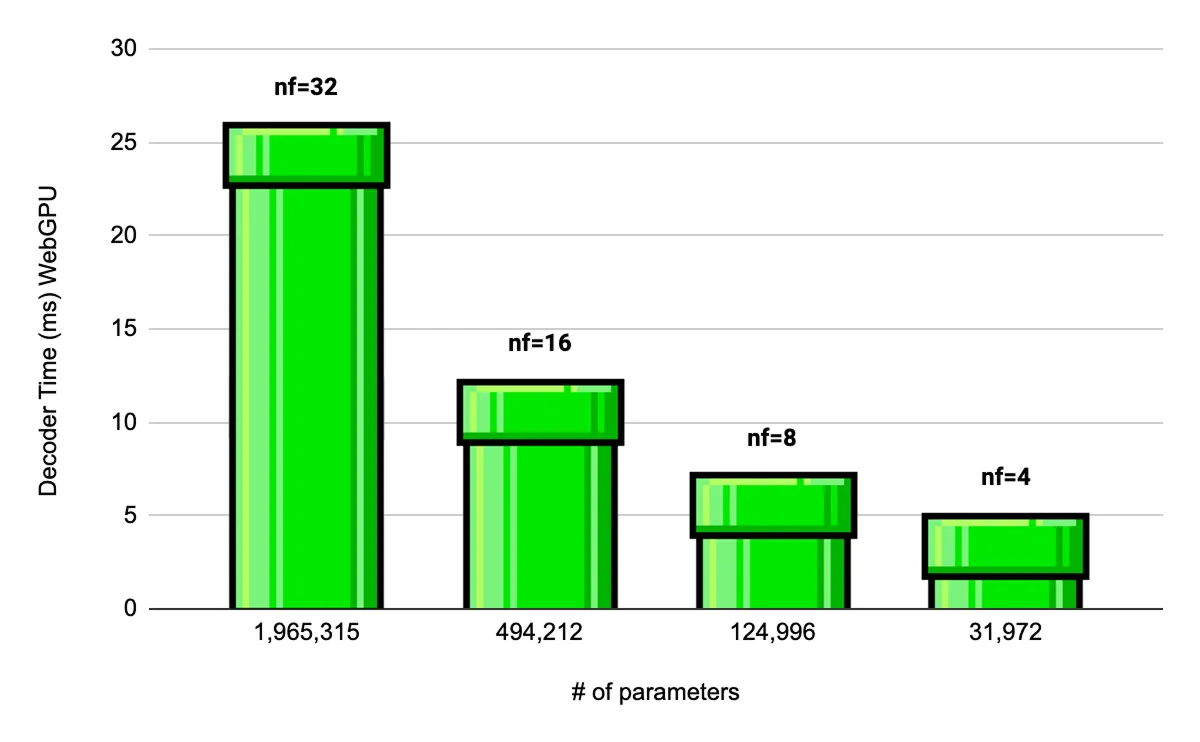
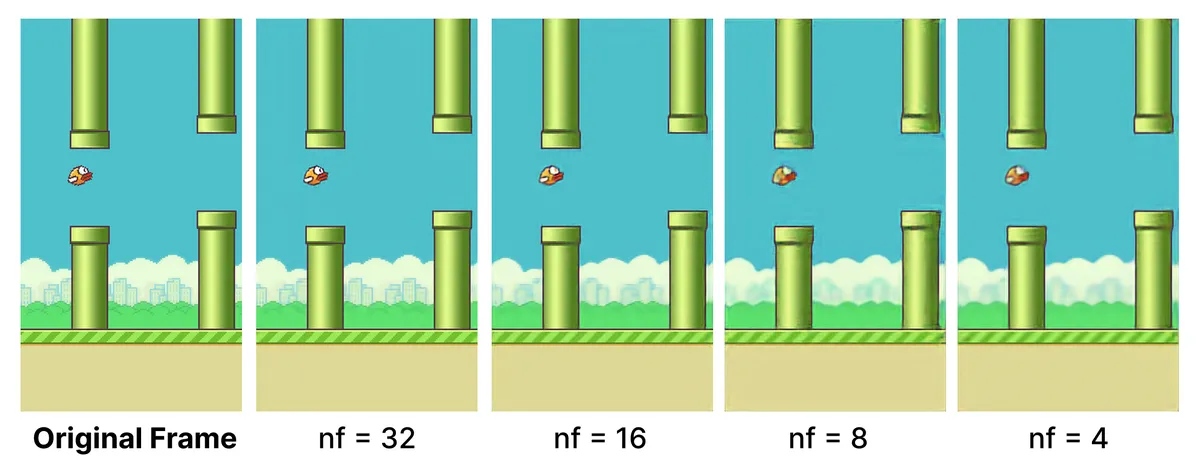
(top) Decoder WebGPU inference time (bottom) Reconstruction quality across different channel widths
I tested different channel widths to find the best balance between speed and quality. At channel width 4, there’s some loss in finer details, but the reconstruction quality is still good enough for gameplay. With this channel width, replacing the upsampler with the high-compression autoencoder increases the frame rate by 2x.
Denoiser: 25.8ms - 78.4% of total
Decoder: 6.5ms - 19.8% of total
Display: 0.6ms - 1.8% of total
Total per frame: 32.9ms
Estimated FPS: 30.4
Mobile Settings, WASM fallback
WebGPU is still being rolled out on mobile devices and was enabled by default in iOS 18. Since GPU-accelerated inference is still in the early stages for mobile devices, I chose to fallback to WebAssembly (WASM) for older devices. As a result, we aren’t able to take advantage of any GPU parallelization, so WASM devices get about a 2-3x reduction in speed compared to WebGPU. I also found WASM had several issues while testing, such as memory limits and broken WASM-SIMD instructions on older devices.
There are two strategies I see for getting real-time world models to run well across all devices. The first is to wait for WebGPU to fully mature and older devices to deprecate, but this takes time and many people still run older mobile OS versions. The alternative is adding support for something like WebGL, like in Ollin's demo. WebGL is an older standard and is honestly more painful to work with, but has much broader compatibility across devices.
In the future, I’d like to explore more WebGPU kernel optimizations and run a hybrid approach with WebGL fallback for any unsupported devices. For now, we fallback to WASM when WebGPU isn’t available and accept the performance hit. Fortunately, the prior model reduction experiments still benefit WASM, and I can get about 12-15 FPS on my iPhone 14 Pro A16 Bionic (5-core GPU).
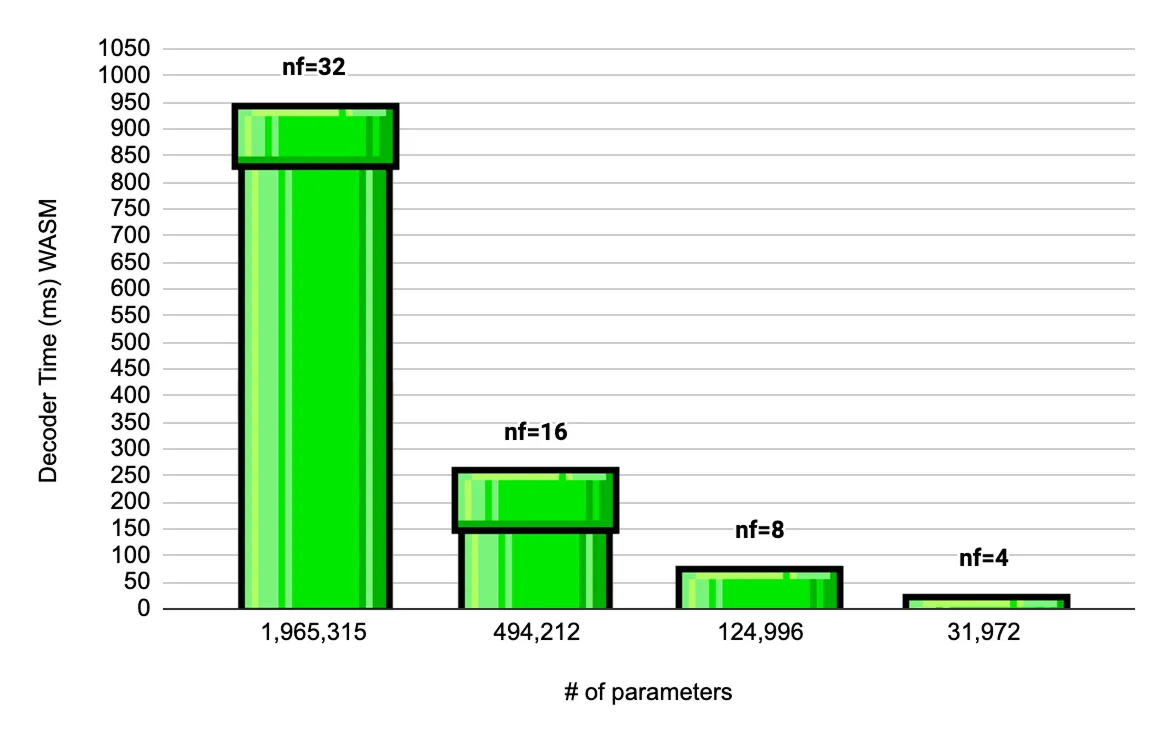
Decoder WASM inference times across different channel widths
Denoiser: 50.2ms - 69.0% of total
Decoder: 22.1ms - 30.4% of total
Display: 0.6ms - 0.8% of total
Total per frame: 72.9ms
Estimated FPS: 13.7
Conclusion
Overall, these optimizations get the model to 30 FPS on my laptop and 12-15 FPS on mobile. There are some interesting avenues that we can build off this initial project. Flappy Bird is a simple example, but I think it serves as a good proof of concept for what is possible when we optimize for constrained environments.
- Fix game coherence issues: The 1-step denoising causes blurry crash sequences and reduces pipe variety. I think exploring better sampling techniques could help maintain quality while preserving speed.
- Integrate audio: I would like to add audio encoding in the future to enable a joint video-audio world model, similar to Veo3. Wayfarer Labs is exploring this direction with their CSGO prototype.
- Scale to 3D games: 3D games add a lot of complexity and might need different architectures (DiTs, VQGAN, Diffusion/Self Forcing) since UNet diffusion models may struggle with the real-time 3D rendering constraints.
- Real-time style control: Something like ControlNet but for world models, where I could change backgrounds or characters mid-game with text prompts. Decart released an impressive real-time style transfer demo with Mirage recently.
Special thanks to Ollin for fielding all of my questions during this project, and to members of the DIAMOND discord for the training guidance and feedback.