How do you extend Sora to a “world model” feed?
I’ve been using Sora for a week now (some of my creations), and I think feeds are the correct form factor for learning how to use generative media models at scale.
Early generative media products followed a pattern where I’d open up a standalone interface, and I'd have to figure out what generations were possible on my own. Eventually, I’d run out of ideas because I didn’t understand how to use the model intuitively.
Midjourney solved this by throwing users into Discord channels to learn how to use the model together. Now, I could see other users' generations, grab their prompts, and remix their creations. With millions of users doing this, it starts a flywheel that reveals what users are creating and where the model needs to improve. Feeds are a natural extension of this behavior.

Good example of how remix culture translates across domains. On TikTok you duet a video and create variations that chain together into completely different takes. Sora enables the same pattern, where each remix can extend the previous prompt and evolve the concept. The video outputs are never perfect, but the model excels at creating ideas you can iterate on. (Tiktok, Sora)
So what comes next?
I think the next evolution will be feeds built around world models, and I predict we’ll see a product launched around this soon. I sketched out two examples of this below1.
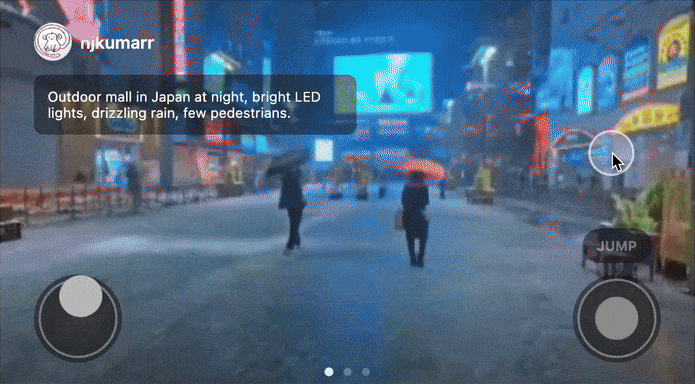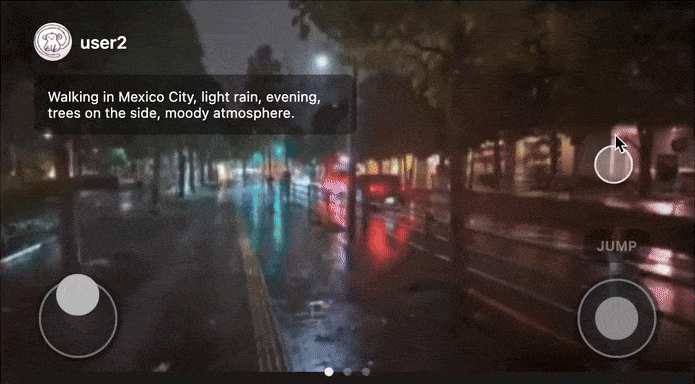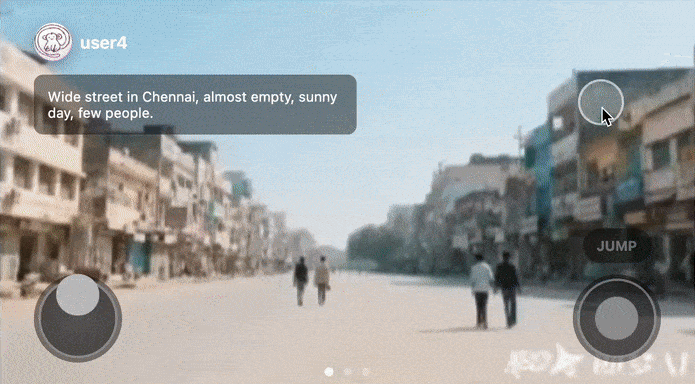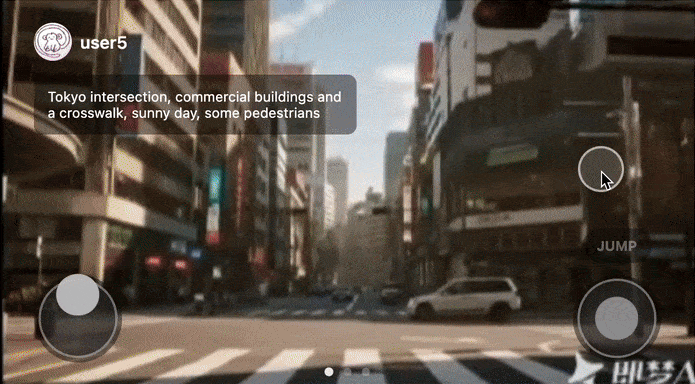
Users could open a feed, interact with a game, swipe up and discover a new world, and repeat.
Julian Togelius highlighted this when Genie 3 launched, predicting that a social media use case would emerge where users could create and share small, playable experiences. Feeds are a natural medium for this because they lower the barrier to discovery. You could scroll and watch others generate worlds, and within a couple of minutes grab mechanics or prompts and start creating. World models are still early and most people haven’t had a chance to use them yet, so the social learning aspect seems crucial.
Video games haven't adopted this short-trend cycle yet. Game developers can't rapidly remix ideas like video creators, mainly because you can't build a game as fast as you can record a video. Even with a great idea, you still need to code the mechanics, generate the assets, and have the skills to ship quickly while the trend is still relevant. I see glimpses of this on Roblox, where trend-based games pop up on the front page frequently. However, you still need technical expertise to build reusable templates and assets, which limits who can create these games.
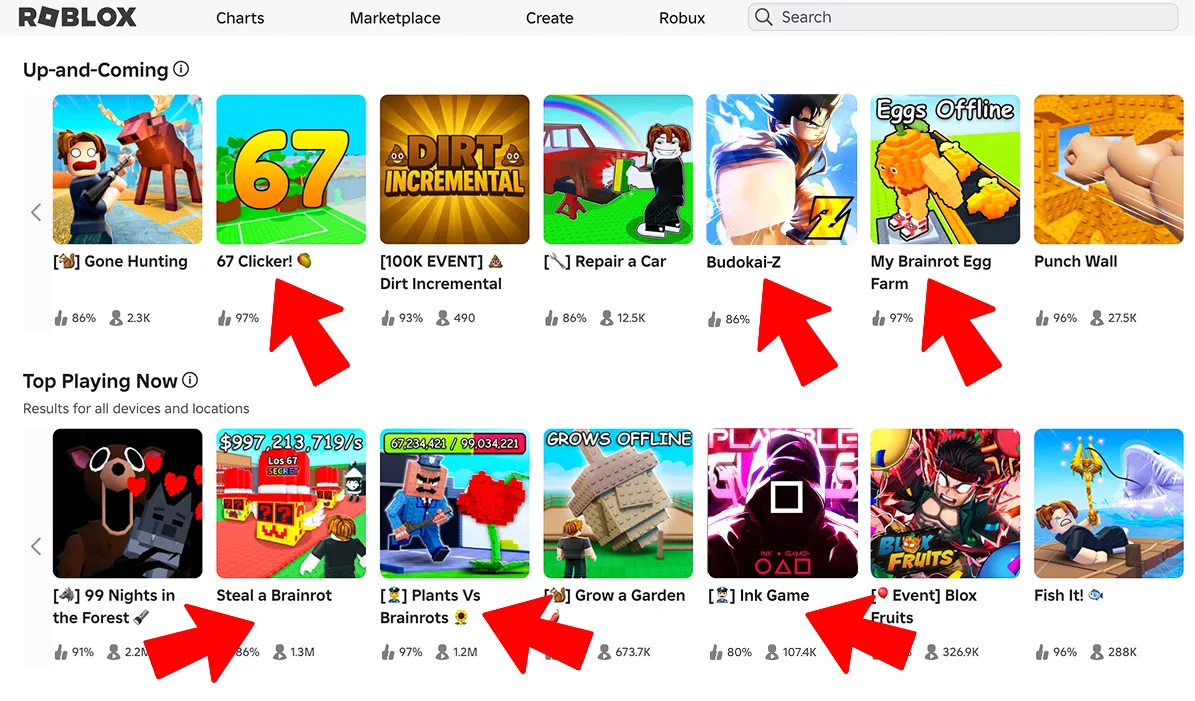
Front page of Roblox -> multiple trend-derived games which often follow repeatable game templates.
Genie 3 signals that this is going to change, just like Sora is signaling it for video creation. None of these games will replace any AAA experience, but I think that’s fine. It’ll still be fun to experiment and share brief interactive games with other people.
Current Challenges
A couple of challenges stand out to me when thinking about a feed around these games. With world model inference, you're essentially live-streaming video generation at scale, which presents a whole set of infrastructure challenges. It's also worth designing these systems from the ground up to anticipate how users would interact with world models.
Inference
Cost: Serving video models at scale is already pretty expensive, and OpenAI has put several constraints around Sora. The generations are limited to 15 second clips that take a couple of minutes to produce, and the app is invite-only to manage demand. World models need even longer durations and coherence to create meaningful playable experiences, which exacerbates this problem. Serving Genie 3 at the moment seems really expensive, and I’m wondering how you reduce costs significantly while maintaining quality in the outputs.
Latency: The latency between the GPU and the end user needs to be low enough that it feels instant. Some world model products I’ve tried have control lag issues between the inputs and what the model generates on screen. What is the acceptable latency to make this feel real-time? What optimizations are needed for both the model and the GPU infra to hit that target? For a feed with a lot of concurrent users, any significant lag is going to kill the experience.
On-device inference: Could you run these models on-device instead? Running world models directly in the browser with a native graphics API like WebGL or WebGPU could eliminate any latency or demand issues, you’d just be interacting with a local model on your phone - see my previous post and Ollin Boer's on-device work for a demo - This limits the model's size and complexity, but could you train a powerful base model and distill it heavily to a smaller version that runs on edge devices? Figma invests heavily in client-side rendering with WebGL/WebGPU to make the canvas feel instant. A similar investment in distillation and graphics optimization could make on-device models possible.
Feed Design
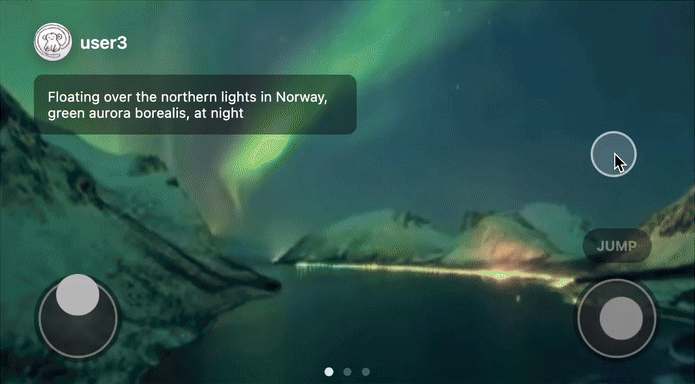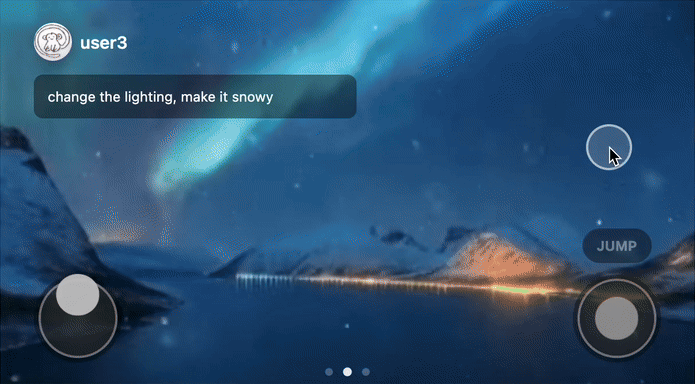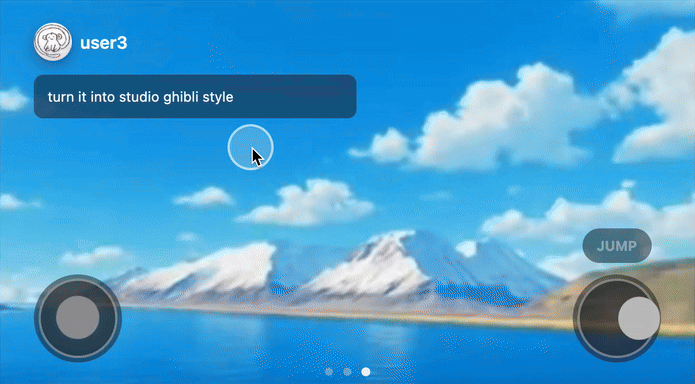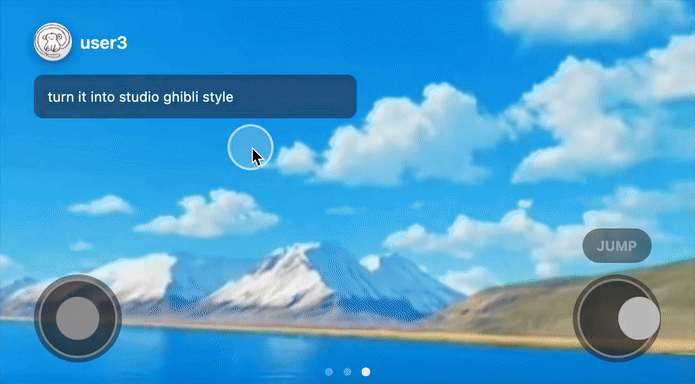
Remixing of world models
Creation: What inputs could users provide when creating or remixing a game? Beyond prompts or reference images, can users record videos directly or specify the physics and mechanics they want in a prompt? Can these input methods work across different game types? There’s a challenge in making this simple enough to use while allowing flexibility to produce diverse content.
Recommendation: World models create new active participation signals beyond passive video metrics like watch time and likes. For instance, do players explore the whole world or do they stand in specific areas? How much do they engage with the game mechanics? Are there certain spawn points that lead to longer exploration? How do you balance recommending popular worlds versus prioritizing discovery of diverse worlds?
Moderation: With video, you can scan frames and audio transcripts to catch policy violations at the creation point. World models are harder to moderate because the content changes based on a player's actions, and it’s impossible to test every path a player might take. I’m wondering if this means putting more emphasis on creation guidelines and blocking certain mechanics or prompts. Is it possible to record playthroughs automatically with a bot beforehand and flag them for moderation?
I wouldn’t be surprised if big labs are already working towards this. Even having limited demos that can be generated in a couple of minutes would be a great way to introduce world models to consumers, just like it’s been done for images and video. Could be a fun project to work on.
Videos are sourced from the YUME model paper.↩